The AI Supply Chain
A Web of Digital Life
Explore the massive, interconnected ecosystem that makes modern Artificial Intelligence possible—from power grids to your screen.
The Primary Producers: Energy and the Power Grid
The Foundation of AI
In our AI ecosystem, the Power Grid is the primary producer, the equivalent of the sun and plants that capture its energy. Without a massive, reliable supply of electricity, the entire system collapses.
Key Insight
Data centers accounted for 4% of total U.S. electricity use in 2024. Their energy demand is expected to more than double by 2030.
The largest consumers of this energy are Data Centers, the physical homes of AI. These facilities house the servers and chips that train and run Large Language Models (LLMs). This energy is not just for running the chips; a significant portion is used for cooling the heat generated by the intense computation.
1Power Consumption Metrics
A single large data center can consume between 20-100 megawatts (MW) of power—equivalent to the electricity needs of 15,000-75,000 homes. Hyperscale facilities operated by tech giants can exceed 200 MW.
2Cooling Systems
Data centers use Power Usage Effectiveness (PUE) as a metric, where 1.0 is perfect efficiency. Modern facilities achieve PUE of 1.2-1.3, meaning 20-30% of energy goes to cooling. Advanced liquid cooling systems are being deployed to handle high-density AI chip racks.
3Renewable Energy Transition
Major AI companies are investing heavily in renewable energy. Google reports 64% carbon-free energy usage, while Microsoft aims for 100% renewable energy by 2025. However, the sheer scale of AI growth challenges these sustainability goals.
4Grid Impact
The rapid expansion of AI infrastructure is straining electrical grids in tech hubs. Some regions are experiencing delays in data center construction due to insufficient grid capacity, prompting investments in dedicated substations and transmission lines.

The Master Builders: ASML and the Foundation of Silicon
Creating the Tools
If the power grid is the sun, then the next crucial component is the Master Builder—the single, indispensable organism that creates the tools for the entire web. This role is held by ASML, a Dutch company that holds a near-monopoly on the Extreme Ultraviolet (EUV) lithography machines.
Key Insight
ASML's EUV machines are essential for etching microscopic circuits onto silicon wafers, creating the most advanced microchips.
These massive, complex machines are the only way to manufacture cutting-edge chips required for modern AI. Without ASML's technology, the AI revolution would not be possible.
1EUV Machine Specifications
Each EUV lithography machine costs approximately $200 million, weighs 180 tons, and requires three Boeing 747s to transport. They use 13.5-nanometer wavelength light to etch features as small as 3-5 nanometers on silicon wafers.
2Manufacturing Process
EUV machines generate extreme ultraviolet light by firing 50,000 laser pulses per second at microscopic tin droplets, creating plasma that emits the required wavelength. The entire process occurs in a near-perfect vacuum with mirrors that are the smoothest objects ever made—if scaled to the size of Germany, imperfections would be less than 1mm.
3Supply Chain Monopoly
ASML is the sole manufacturer of EUV lithography systems, with no competitors capable of producing equivalent technology. This creates a critical bottleneck in the global semiconductor supply chain, making ASML strategically important for national security and economic competitiveness.
4Next-Generation Technology
ASML is developing High-NA (Numerical Aperture) EUV systems capable of 8-nanometer resolution, enabling future chip generations at 2nm and below. These next-gen machines cost $400 million each and require entirely new cleanroom infrastructure.

The Digital Brains: Chips and Data Centers
The Physical Intelligence
The chips, manufactured using ASML's tools, are the Primary Consumers in our web. They are the physical brains of the AI system, housed within the massive Data Centers.
Key Insight
Data centers are purpose-built to house thousands of servers, each containing specialized chips—primarily Graphics Processing Units (GPUs)—optimized for parallel processing.
The chips serve two main functions: Training (the initial, massive computational process where the LLM learns from vast amounts of data) and Inference (the process of using the trained model to generate responses).
1GPU vs CPU Architecture
While CPUs have 8-64 cores optimized for sequential processing, modern AI GPUs like NVIDIA's H100 contain 16,896 CUDA cores designed for parallel matrix operations. This architecture makes GPUs 10-100x faster for AI workloads than traditional CPUs.
2Tensor Cores & AI Acceleration
Modern AI chips include specialized Tensor Cores that accelerate matrix multiplication—the fundamental operation in neural networks. NVIDIA's H100 delivers 1,000 teraflops of AI performance using mixed-precision computing (FP8/FP16), dramatically reducing training time and energy consumption.
3Interconnect Technology
Training large models requires thousands of GPUs working in parallel, connected via high-speed networks like NVIDIA's NVLink (900 GB/s) and InfiniBand (400 Gbps). Network latency and bandwidth are often the bottleneck, not compute power.
4Memory Hierarchy
AI chips feature complex memory hierarchies: on-chip SRAM caches (tens of MB), High Bandwidth Memory (HBM3 at 3.35 TB/s), and system DRAM. The H100 has 80GB of HBM3 memory—essential for holding billion-parameter models during training.
5Data Center Infrastructure
Modern AI data centers are organized into pods of 256-1024 GPUs, with dedicated cooling, power distribution, and network fabric. A single training cluster for frontier models can contain 10,000-100,000 GPUs, costing hundreds of millions of dollars.

The Digital Predators: LLMs and Chip Consumption
Consuming Processing Power
The Large Language Models (LLMs) themselves are the Digital Predators—the sophisticated software that consumes the processing power of the chips.
Key Insight
Training requires brute-force computation with high power draw over long periods. Inference requires precision and speed with lower power per query, but extremely high volume.
The demand for faster and more efficient chips is driven by the need to reduce the cost and latency of inference, as this is the process that scales with the number of users.
1Training Compute Requirements
GPT-3 (175B parameters) required 3,640 petaflop-days of compute—equivalent to running 10,000 GPUs for a month. GPT-4 is estimated to have used 25,000-50,000 GPUs for 3-6 months, consuming 50-100 megawatt-hours of electricity and costing $50-100 million.
2Model Scaling Laws
Research shows that model performance scales predictably with three factors: model size (parameters), dataset size (tokens), and compute budget (FLOPs). Doubling model quality requires roughly 10x more compute, following power-law relationships discovered by OpenAI and DeepMind.
3Inference Optimization
While training is compute-intensive but infrequent, inference must be fast and efficient for millions of queries. Techniques like quantization (reducing precision from FP32 to INT8), pruning (removing unnecessary connections), and distillation (creating smaller student models) reduce inference costs by 5-10x.
4Batch Processing & Latency
Inference systems balance throughput (queries per second) and latency (response time). Batching multiple requests together improves GPU utilization from 20% to 80%+, but increases latency. Dynamic batching algorithms optimize this tradeoff in real-time.
5Cost Economics
For a model like GPT-4, inference costs dominate after ~10 million queries. At scale, serving 1 billion queries costs more than the initial training. This drives the industry toward more efficient architectures and specialized inference chips.
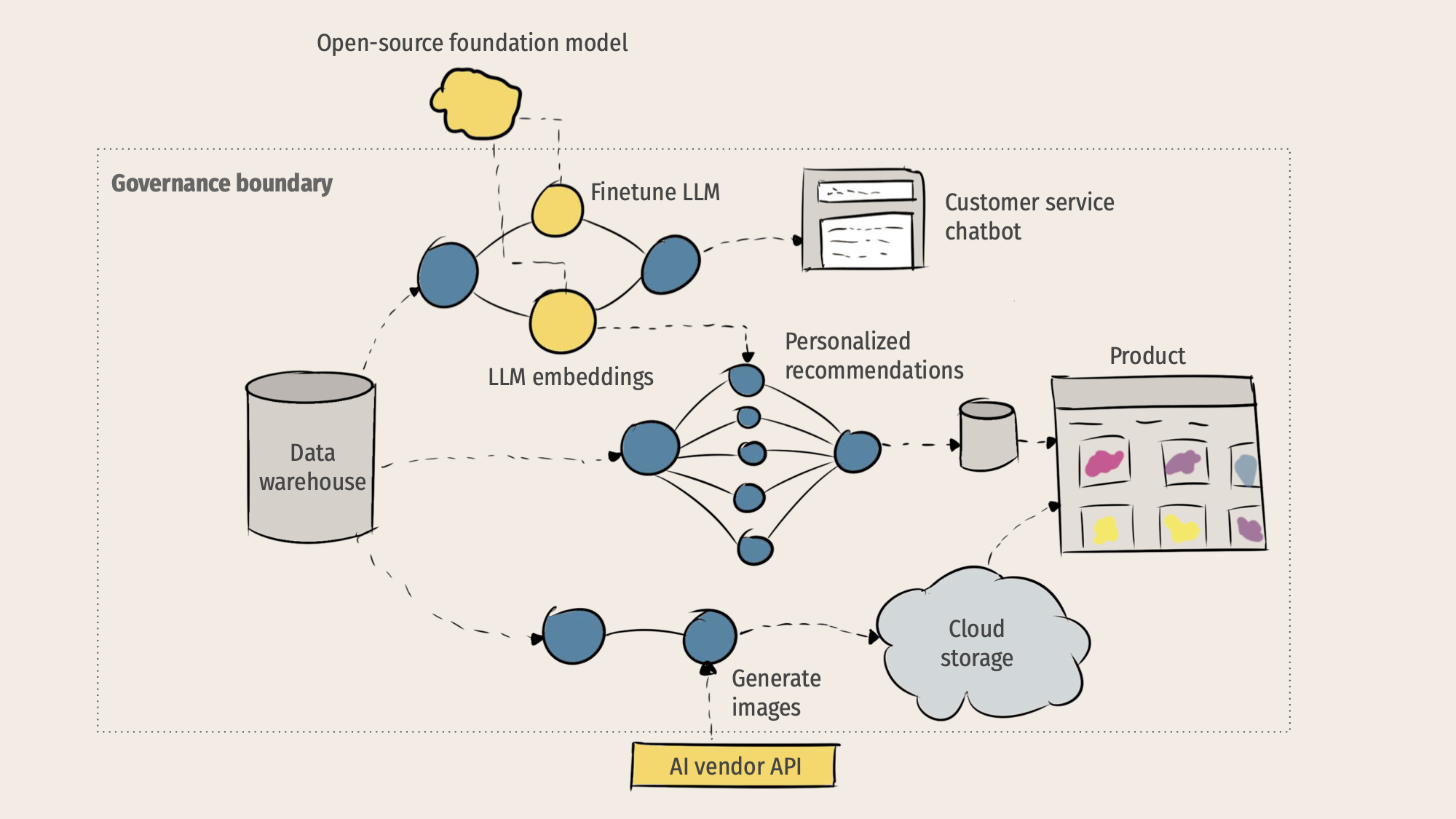
The Digital Hunters: LLMs Delivering Results
From Query to Action
The LLMs act as Digital Hunters or agents, using their processing power to deliver results to the user. This delivery can take two forms:
Key Insight
Enquiry (Simple Response): The model directly answers a question. Agentic Tasks (Complex Action): The model plans, acts, and uses tools to solve complex problems.
For example, an agentic LLM might search the web, read multiple sources, synthesize the findings, and then produce a comprehensive, cited report. This multi-step process consumes more chip resources per task.
1API Infrastructure
Modern LLM APIs handle millions of requests per day through distributed systems with load balancing, rate limiting, and geographic routing. OpenAI's API infrastructure uses Kubernetes clusters across multiple cloud regions, with automatic failover and horizontal scaling.
2Prompt Engineering & Context
API calls include system prompts (instructions), user prompts (queries), and conversation history (context). Context windows have grown from 2K tokens (GPT-3) to 128K+ tokens (GPT-4 Turbo), enabling complex multi-turn conversations and document analysis.
3Agentic Workflows
Agentic AI systems use techniques like ReAct (Reasoning + Acting), where models alternate between thinking and tool use. They can call external APIs, search databases, execute code, and chain multiple steps together—consuming 10-100x more compute than simple queries.
4Tool Integration
Modern LLM agents integrate with function calling, allowing them to invoke external tools (web search, calculators, databases, code interpreters). This transforms LLMs from text generators into general-purpose reasoning engines capable of complex task automation.
5Multi-Modal Capabilities
Next-generation models process text, images, audio, and video simultaneously. GPT-4 Vision can analyze images, while models like Gemini handle video understanding. This multi-modal processing requires specialized neural architectures and increases compute requirements by 2-5x.

The Final Link: User Digestion
Completing the Cycle
The final stage of the web is the User, who acts as the ultimate consumer and, crucially, the source of new data.
Key Insight
Every interaction, every query, and every piece of feedback the user provides becomes new data that fuels the next generation of LLM Training.
The user reads, analyzes, and applies the information provided by the LLM. This feedback loop completes the web, turning the final consumer into a new primary producer of information, ensuring the cycle continues.
1Reinforcement Learning from Human Feedback (RLHF)
Modern LLMs are fine-tuned using RLHF, where human evaluators rank model outputs. These preferences train a reward model that guides further training. ChatGPT's quality improvements came largely from RLHF using thousands of human feedback examples.
2Data Collection & Privacy
User interactions generate valuable training data, but raise privacy concerns. Companies use techniques like differential privacy, data anonymization, and opt-out mechanisms. OpenAI allows users to disable data collection, while enterprise APIs guarantee data isolation.
3Continuous Learning
Unlike traditional software, LLMs can improve continuously through user feedback. Online learning systems update models in real-time, while batch systems retrain periodically. This creates a flywheel effect where more usage improves quality, attracting more users.
4Alignment & Safety
User feedback helps align models with human values and safety requirements. Red teaming (adversarial testing), constitutional AI (rule-based constraints), and iterative deployment (gradual rollout) use user interactions to identify and fix harmful behaviors.
5The Data Flywheel
Companies with large user bases have a structural advantage: more users → more feedback → better models → more users. This network effect creates winner-take-most dynamics in the AI industry, similar to social media platforms.

A Delicate Balance
The AI supply chain is a delicate, resource-intensive web. From the terawatts of electricity drawn from the power grid to the microscopic precision of ASML's machines, and finally to the user's screen, every link is vital.
Understanding this web—its energy demands, its technological bottlenecks, and its reliance on user interaction—is key to understanding the future of Artificial Intelligence.